Other computer vision tasks
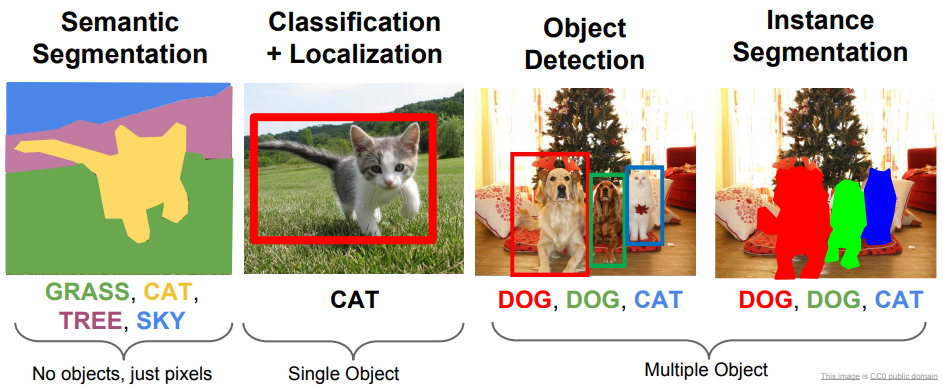
Semantic Segmentation
output the pixel of segment
grass/cat/tree/sky (category label)
label each pixel in the image with a category label
dont defferentiate instances, only care about pixels
idea: sliding window
take crops, what is the center of this crop , apply on crop rather than whole image
this is computationally expensive
idea2 : fully convolutional
input 3 x H x W
convolution
conv
conv
scores: CxHxW ( C : # of categories)
Predictions:HxW
getting training data is super expensive
what is the loss function? on every pixel cross entropy , sum of average, mini batch
deconvolution
transpose convolution
모든 픽셀에 카테고리를 정함
sematic segmentation: 암소 두마리는 구별 못함, instance segmentation: 이를 해결
sliding window는 비용이 크고 , 경계에도 공유 피쳐가 많아서 안좋음
fully convolutional network : 이미지 영역을 나누고 독집적으로 분류하는것이 아님.
FC layer가 없고 conv layer 로만 구성된 네트워크
출력의 모든 픽셀과 ground truth 간의 cross entropy
모든 픽셀의 카테고리를 알고있다는 가정이 필요 ( imgae classification과 마찬가지임)
입력이 고정되어야하기때문에 특징맵을 downsampling/ upsampling함
convolution in downsampling을 반복함
image classification 과 유사해보이지만. fc layer이 없고 다시 spatial resolution을 다시 키움
네트워크가 lower solution을 처리하여 네트워크를 깊게만듬
unpooling - maxunpooling, nearest neighbor, bed of nails, ... => 고정된 함수 , 학습은 없음
transpose convolution -

sliding window 라고 하는 기법으로, 사진을 윈도우 사이즈에 맞춰 나눈 다음 윈로우로 잘린 이미지를 입력값으로 모델을 통과해서 결과를 얻음
모든 영역을 작은 영역으로 잘라서 모델에 넣기 때문에 연산 횟수가 많다
서로 다른 영역이 인접해 있는경우 그 특징을 공유한다

일반적인 cnn 구조에서 FC layer를 빼고 input과 output의 사이즈가 동일하게 나옴 (with downsamplin, upsampling)
Upsampling

Learnable upsampling : Transpose Convolution
입력값이 필터에 곱해지는 가중치 역할을 함. 출력 = 필터 * 입력(가중치)

Classification + Localization
in addition to class label, we want to draw the box(es)
we have fixed number of objects that you are looking for
localization에서는 객체가 하나.
box coordinate 하는 fc가 하나 더있음

Object Detection
start with fixed set of category labels that we are interested in,
draw boxes on every intances
이미지분류 + bounding box -> object detection
이미지가 몇개인지 예측하기가 어렵기때문에 앞의 localization regression을 이용해서 풀기는 까다로움

객체가 있을법한 후보(region proposal)을 찾기. 뭉친곳을 찾아냄
있을법한 region proposals을 CNN의 입력으로 해서 추출

Image => RPN(region proposal network) => 2000 ROI(region proposal of interest) => 사이즈보정(fc layer..) =>

Faster R-CNN

전체 이미지에 대해서 CNN => 전체 이미지에 대한 고해상도 feature map
ROI 계산
CNN feature map에 ROI를 projection - feature map 에서 가져옴
Instance Segmentation
final goal: detect all the instances of the categories we care about
Mask R-CNN

CNN과 RPN Rjcla
RPN의 ROI를 뜯어냄
BBox마다 segmentation mask를 예측하도록 함 (segmantic segmentation)
'AI > CS231n' 카테고리의 다른 글
| CS231n- Lec13. Generative Models (0) | 2023.09.18 |
|---|---|
| CS231n - Lec12. Visualizing and Understanding (0) | 2023.09.18 |
| CS231n - Lec10. Recurrent Neural Networks (0) | 2023.09.15 |
| CS231n - Lec9. CNN Architecture (0) | 2023.09.12 |
| CS231n-Lec8. Deep Learning Software (0) | 2023.09.11 |



