
1 image - fixed size output vector
2 image captioning
3 sentiment classification (positive/negative)
4 translation
5 video classification (each frame)
sequential processing of fixed outputs
RNN
가변 input 가변 output
input - RNN (has internal hidden state) -output (usually wnat to predict a vetctor at some time steps)


vanilla recurrent neural network ( a state consists of a single hidden vector h )

h,x 는 매번 달라지지만 W는 동일
왜 tanh 사용? -> 이후 lstm 배울때 나옴
이전에 backward pass 시 dLoss/dW 를 계산하려면 행렬W의 gradient 를 전부 더해줬음
이 RNN모델의 back prop을 위한 행렬 W의 그래디언트를 구하려면 각 스텝에서의 W에 대한 그래디언트를 전부 계산한 뒤에 이 값들을 모두 더해주면 된다.
encoder : many to one
decoder : one to many
Example: Character-level language model sampling

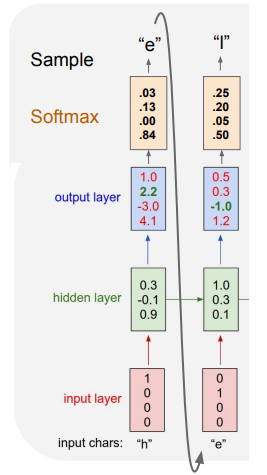
sampling을 어떻게 해서 저렇게 나온지 모르겠다..
운좋게 e가 나온다고 함..
확률분포에서 샘플링, 그냥 가장 높은값 등 여러가지 방법이 있는데
확률분포에서 샘플링 하는 방법을 사용하면 일반적으로 모델에서의 다양성을 얻을 수 있음
test time에 softmax vector를 one hot vector대신에 넣어줄 수 있음?
problem
1. train time 에서 보지 못한 입력과 달라져서 모델이 아무것도 못하게됨
2. 실제로는 vocabularies 가 아주 커서 one hot vector를 sparse vector operation으로 처리하는것이 좋음
Mini-batch처럼 truncated backpropagation을 사용할 수 있음.
train time에 한 스텝을 일정 단위로 자름. 100개 forward, loss 계산, gradient step ...
latent structure를 알아서 학습함 - 셰익스피어, Ccode ...
Image Captioning
Failure cases

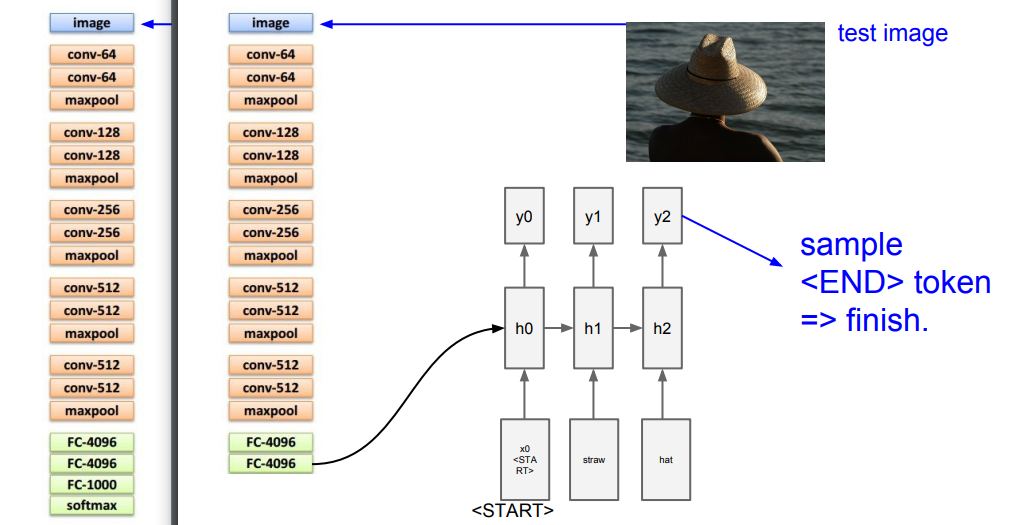
4096?

이러한것들은 supervised learning으로 되어서 natural language model 이 있는 이미지를 가지고있어야함
(ex. microsoft coco dataset)
Image Captioning with Attention(for explaining LSTM)
벡터가 공간정보를 가지고있는 LxD의 모양을 만들어냄
모델이 이미지에서 보고싶은 위치에 대한 분포를 만들어냄



gradient clipping: gradient가 발산하면 잘라버림
vanishing 하면 해결 방법이 없음
RNN은 연속된 데이터를 처리 앞과 뒤의 인과관계가 사라짐

LSTM (LONG SHORT TERM MEMORY)
C_t라는 cell state라는 두번째 벡터가 있음.
필요한 정보들을 cell state 에 보관
두개의 입력을 받음. H(t-1), x(t) => 4개의 gate 계산
vanilla RNN에서도 마찬가지로 입력 두개 받음, 행렬곱 연산을 통해 hidden state를 구함
잊으려면 0, 기억하려면 1에 가까운 값이 좋기때문에 효율이 안좋은 sigmoid, tanh 사용



backpropa 할때, 덧셈이기때문에 수월함 => Uninterrupted Gradient Flow

'AI > CS231n' 카테고리의 다른 글
| CS231n - Lec12. Visualizing and Understanding (0) | 2023.09.18 |
|---|---|
| CS231n - Lec11. Detection and Segmentation (0) | 2023.09.17 |
| CS231n - Lec9. CNN Architecture (0) | 2023.09.12 |
| CS231n-Lec8. Deep Learning Software (0) | 2023.09.11 |
| CS231n - Lec7. Training Neural Networks 2 (0) | 2023.09.11 |


